



Spread.NET 13 WinForms 및 동적 배열 함수
페이지 정보
작성자 GrapeCity 작성일 2020-07-28 11:08 조회 2,231회
댓글 0건
작성일 2020-07-28 11:08 조회 2,231회
댓글 0건
본문
관련링크
WinForms용 Spread.NET 13에는 동적 배열과 FILTER, RANDARRAY, SEQUENCE, SORT, SORTBY 및 UNIQUE 총 6가지 중요한 새 기능이 지원됩니다. 이 글에서는 이러한 새로운 기능에 대해 자세히 설명합니다.
Spread.NET 출시 관련 글 읽어보기
이러한 함수를 설명하기 위해 함수와 해당 인자에 대해 서술하는 각 새 함수에 대한 워크 시트를 만들었습니다. 또한 명확한 설명을 위해 몇 가지 예 또한, 보여 드리도로 하겠습니다.
이 워크 시트는 통합 문서에 첫 6개 워크 시트입니다.
Spilled_Array_Function_Examples 다운로드
Spread.NET 13 Windows Forms에 포함된 Spread Designer 도구도 사용할 수 있습니다. 홈페이지에서 30일 무료 평가판을 다운로드하여 XLSX 파일을 열고 예제에 따라 진행해보세요.
필터
필터 구문
FILTER(array,include,[if_empty]) |
|
array |
필터에 대한 참조 또는 배열입니다. |
include |
필터 조건 - 아래 예시 참조 |
[if_empty] |
필터 결과가 비어있을 때, 반환할 옵션값입니다. |
Filter 함수는 범위 또는 배열을 가져와서 특정 기준을 포함하여 필터링된 배열을 반환합니다. 첫 번째 인자 array(배열)은 필터링할 범위 또는 배열을 지정하고 두 번째 인자 include는 포함 기준을 지정하며 옵션값인 세 번째 인자 if_empty는 필터 결과가 비어있을 때 반환할 값을 지정합니다.
if_empty의 인자가 지정되지 않고 필터 결과가 비어있을 때, 함수는 #CALC 오류값을 반환합니다.
FILTER 함수의 실제 사용을 설명하기 위해 FilterData라는 샘플 테이블을 가져왔습니다.
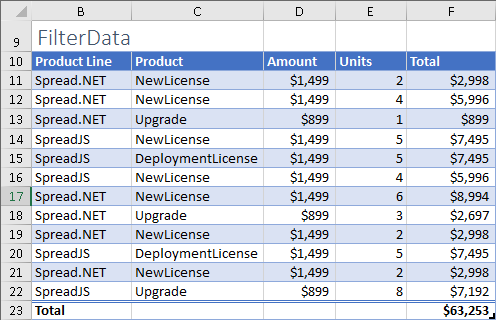
포함 기준을 지정하기 위해서는 = 비교 연산자와 필터링할 값과 함께 필터된 데이터에 따라 길이가 같은 범위 또는 배열을 지정해야 합니다. 필터 데이터가 날짜 또는 숫자 유형인 경우 <, <=,> 및> = 연산자 또한 사용하실 수 있습니다.
예를 들어 Spread.NET 항목만 표시하기 위해 제품 라인(Product Line)별로 위 표를 필터링하려면 다음 수식을 사용해야 합니다.
=FILTER(FilterData,FilterData[Product Line]="Spread.NET")
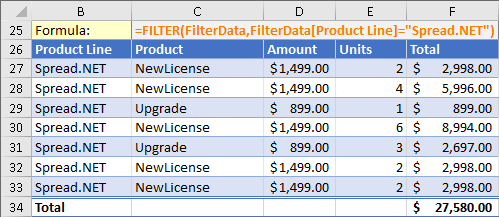
B27:F33의 위 결과는 테이블처럼 표시되도록 형식이 지정되어 있지만 동적 배열 수식과 테이블 셀에서 지원되지 않기 때문에 실제로는 테이블이 아닙니다. 대신, 범위는 표처럼 보이도록 형식이 지정되며 테이블의 헤더 셀인 B26:F26은 원본 테이블의 헤더 셀의 복사본일 뿐입니다.
34행의 합계는 셀 F34의 수식을 포함하여 수동으로 추가되며 위의 셀을 합산합니다 ( Spread.NET 13 WinForms에서 Alt + = 키보드 단축키를 사용하여 이러한 수식을 삽입할 수 있음).
수식 참조를 위하여 범위 참조 연산자인 #를 사용하여 셀 B27의 결과는 다시 필터링되고 다른필터(Filter)를 수행할 수 있습니다. 이 예제에서는 명시적 교차를 사용하여 열 참조 C:C 를 사용함으로 기준에 대한 셀 범위를 지정하기 위한 및 범위 교차 연산자 (공백 문자)를 공식 셀 참조 및 보여진 범위 연산자와 함께 사용하여 기준의 셀 범위를 지정하는 방법을 보여줍니다 .
=FILTER(B27#,B27# C:C="NewLicense")
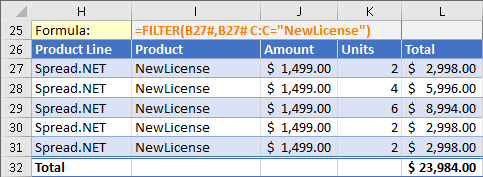
셀 H27에 대한 수식에서 B27# C:C 수식은 B27의 수식에 대해 B27:F33 범위인 셀 범위 B27# 사이에 명시적 교차로 연산자(공백 문자)를 활용하기 위해 범위 교차로 연산자를 사용합니다. C열에 모든 셀을 가르키는 열 범위 C:C은 Product 테이블 열의 셀들이 범위 C27:C33에서 결과를 반환합니다.
필터 기준이 대신 제품에 대해 "배포 라이센스(Deployment Licnese)"를 지정하고 is_empty 인자에 대해 아무것도 지정하지 않으면 필터 결과는 #CALC! 오류와 함께 다음과 같이 나타나게 됩니다. :
= FILTER(B27#, B27# C:C = "DeploymentLicense")

is_empty 인자가 지정되었을 때, 그 값은 대신에 #CALC! 오류로 반환되어 집니다.:
=FILTER(B27#,B27# C:C="DeploymentLicense","NONE FOUND")

괄호로 묶인 여러 필터 기준을 결합하기 위해서 * 및 + 연산자를 사용하면 더 복잡한 필터 조건을 지정할 수 있습니다 .
* 연산자 두 필터 기준을 지정하는"AND"로 지정할 수 있으며 + 연산자는 하나의 Filter 함수 호출로 결합될 수 있도록 두 개 이상의 기준을 허용하는 "OR"로 지정될 수 있습니다.
이 예에서는 두 가지 기준으로 필터링하고 * 연산자를 사용하여 두 조건 모두 충족해야 하는 AND를 지정합니다.
=FILTER(FilterData,(FilterData[Product Line]="SpreadJS")*(FilterData[Product]="DeploymentLicense"))

RANDARRAY
RANDARRAY 구문
| RANDARRAY ([rows], [columns], [min], [max], [integer]) | |
| [rows] | 생성할 난수의 행 수입니다 (기본값은 1). |
| [columns] | 생성할 난수의 열의 수입니다 (기본값은 1). |
| [min] | 생성할 값의 최소값 (기본값은 0)입니다. |
| [max] | 생성할 값의 최대값 (기본값은 1)입니다. |
| [integer] | 정수 값을 반환하면 TRUE입니다 (기본값은 FALSE). |
| RANDARRAY는 워크 시트에서 변경될 때마다 다시 계산되는 휘발성 함수입니다. | |
RANDARRAY 함수는 RAND과 RANDBETWEEN를 구현하는 강력하고 새로운 함수입니다. 어떠한 인자없이 사용할 때, RANDARRAY는 RAND 함수와 동일하게 작동하며 0과 1사이의 단일 난수를 반환하지만 선택적 인자를 지정하면 정수 또는 십진수 값들과 최소값과 최대값을 가진 난수 배열을 생성할 수 있습니다.
RANDARRAY 함수는 자동으로 다시 계산되는 휘발성 함수이며 각 계산주기의 결과의 새로운 난수 배열로 생성할 수 있습니다. 함수는 Monte Carlo 스타일 통계 및 확률 분석을 위한 랜덤 샘플 데이터를 생성하는데 사용될 수 있습니다.
이 예제는 100에서 500사이의 임의의 정수값으로 10행 x 15열 배열을 생성합니다.
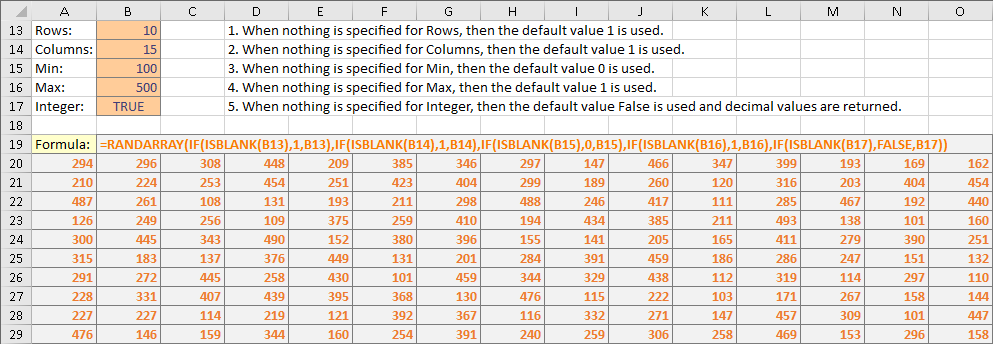
일반적으로 RANDARRAY는 작업의 요구 사항을 충족시키기 위해 필요한 값의 랜덤 배열로 범위를 채우도록 하드 코딩된 인자를 지정하며, RANDARRAY의 모든 인자는 옵션이므로 수식은 어떻게 RANDARRAY 함수가 인자에 대한 입력 셀이 빌어있을 때, 올바른 기본값을 제공하므로 생략되었을 때, 작동하는지 보여줍니다.
=RANDARRAY(IF(ISBLANK(B13),1,B13),IF(ISBLANK(B14),1,B14), IF(ISBLANK(B15),0,B15),IF(ISBLANK(B16),1,B16), IF(ISBLANK(B17),FALSE,B17))
워크 시트에서 다른 조합을 시도하기 위해 인자를 변경하거나 삭제할 수 있으며 RANDARRAY가 각 변경에 대해 새로운 랜덤 데이터를 생성하는 방법에 대해 확인해볼 수 있습니다.
SEQUENCE
시퀀스 구문
| 시퀀스 (rows, [columns], [start], [step]) | |
| rows | 시퀀스에서 생성할 행의 수입니다 (필수 – 제공되지 않은 경우 결과는 #CALC! 오류를 반환합니다). |
| [columns] | 시퀀스에서 생성할 열의 수입니다 (기본값은 1). |
| [start] | 옵션값 - 시작값 (기본값은 1)입니다. |
| [step] | 옵션값 - 증분값 (기본값은 1)입니다. |
SEQUENCE 함수는 매우 간단한 것처럼 보이지만 실제로는 동적 배열에 대해 놀라울 정도로 유연한 애플리케이션으로 매우 강력하고 새로운 함수입니다. 이 함수는 지정된 선택적 시작 및 단계적 증분을 사용하여 값의 시퀀스(Sequence)를 생성합니다.
이 예에서는 5부터 시작하여 5씩 증가하는 순차적인 값으로 10열 x 5행의 배열을 생성합니다.
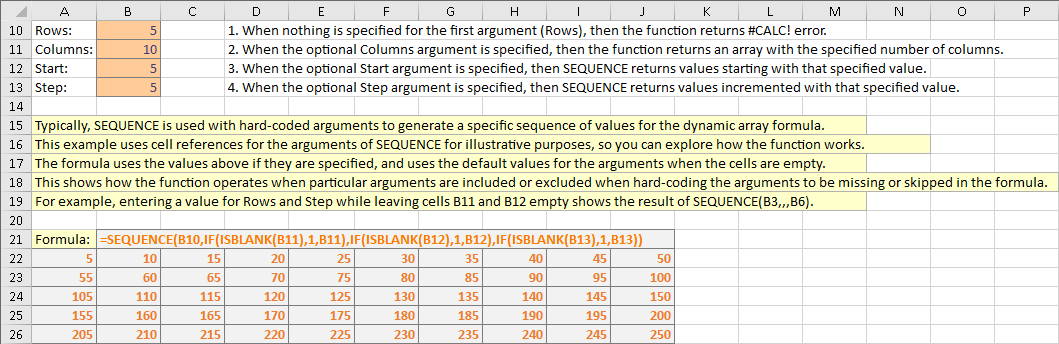
값은 왼쪽에서 오른쪽으로 생성된 다음 위에서 아래로 생성됩니다. RANDARRAY의 예에서 하드 코딩된 인자들과 함께 가장 일반적인 방식으로 함수를 사용하여 시뮬레이션하기 위해 함수 인자에 대한 입력 셀들이 비어있을 때, SEQUENCE의 기본값을 제공하기 위해서 복잡한 수식을 사용합니다.
=SEQUENCE(B10,IF(ISBLANK(B11),1,B11),IF(ISBLANK(B12),1,B12),IF(ISBLANK(B13),1,B13))
워크 시트에서 인자를 변경하거나 제거하여 다른 조합을 시도하고 SEQUENCE의 작동 방식을 확인할 수 있습니다.
SEQUENCE 의 진정한 힘은 다른 함수와의 결합에서 비롯됩니다. 이 예는 SEQUENCE와 TODAY를 사용하여 6주 달력 레이아웃을 생성합니다.
>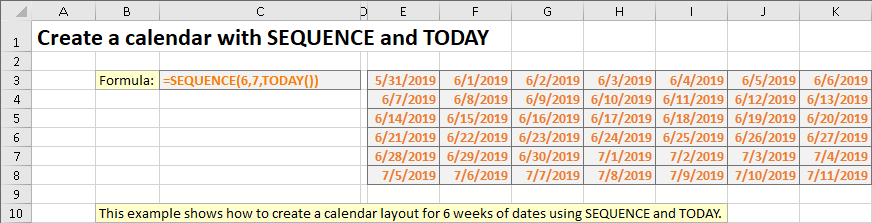
위의 수식은 대신 시작 값에 셀 참조를 사용한 다음 다른 셀 또는 다른 방법으로 날짜를 계산하여 지정된 날짜로부터 시작할 수 있습니다.
이 예제는 SEQUENCE와 NOW를 사용하여 현재 시간부터 시작하여 매 10분마다 시간 슬롯 스케줄을 작성합니다.
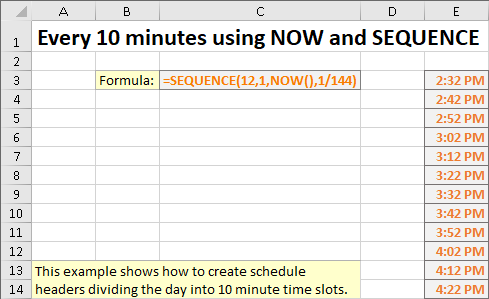
다시 한번, 위의 공식은 NOW 함수를 사용하는 대신 시작 값에 대한 다른 계산 또는 셀 참조를 사용할 수 있습니다.
때때로 SEQUENCE는 동적 배열 함수로 해당 함수를 변환하기 위해 인자들을 생성하는데 유용합니다.
모든 함수에서 작동하지는 않지만 많은 함수의 경우 SEQUENCE 함수를 사용하여 인자 배열을 전달하면 결과가 각 값에 대해 계산합니다.
이 예제는 SEQUENCE 와 함께 LARGE 함수를 사용하여 범위에서 N개의 가장 큰 값의 배열을 반환합니다.
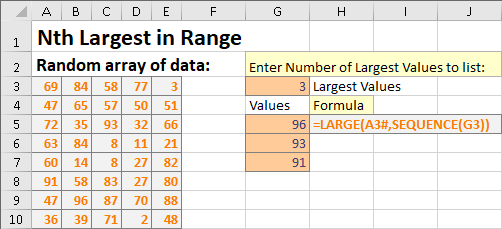
LARGE 함수는 두번째 인자에 대해 스칼라 값을 예상하므로 이 경우, SEQUENCE (G3)를 통과하면 계산이 "가져오게"되고 LARGE 함수가 세 번 수행되개하는 배열 값 "{1;2;3}"은 지정됩니다. 랜덤 데이터 범위에서 세 개의 가장 큰 값을 포함하는 배열 결과를 반환합니다.
이 예제는 SMALL함수를 사용하여 범위에서 N 개의 가장 작은 값의 배열을 반환합니다.
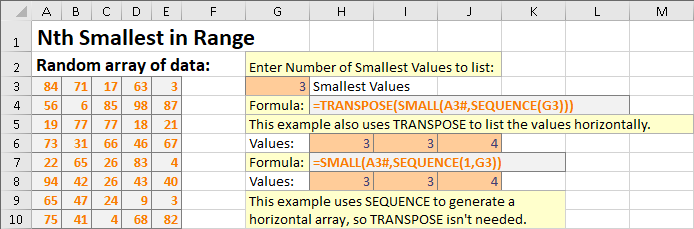
위의 예는 또한 인접한 셀에 유출되는 수직 값 대신 수평을 생성하는 두 가지 다른 방법을 보여줍니다. 첫 번째 방법은 TRANSPOSE 함수를 사용 하여 지정된 배열 값의 열과 행을 바꿉니다. 두 번째 예는 SEQUENCE 함수를 사용하여 세로 대신 가로로 값 시퀀스를 생성하는 방법을 보여줍니다 . 이는 TRANSPOSE 함수 를 사용할 필요가없고 동일한 결과를보다 효율적으로 리턴합니다.
이 SEQUENCE에 대한 마지막 예제는 대시로 구분된 문자들의 시퀀스를 생성하기 위해 SEQUENCE , CHAR, CODE를 함께 TEXTJOIN을 사용합니다.:
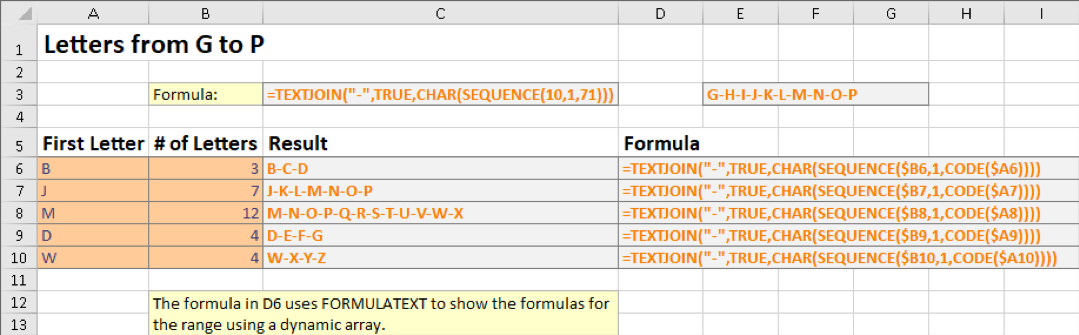
C6:C10 셀의 수식은 열 아래로 복사되지만 D6 셀의 수식은 범위 인자인 C6:C10과 함께 FORMULATEXT 함수를 사용하므로 결과가 인접한 셀로 보여집니다.
SINGLE
SINGLE 구문
| SINGLE (value) | 수식에서 SINGLE 함수를 사용하면 '@'연산자를 사용하여 구문이 자동으로 대체됩니다. |
| @value | |
| value | 수식 셀과 함께 교차할 범위 또는 배열에 대한 참조(첫 번째 요소를 반환함). |
SINGLE 함수와 새로운 @ 연산자는 수식의 이전 버전과의 호환성을 위해 매우 중요한 부분입니다. 동적 배열을 지원하지 않은 이전 버전의 Excel의 스칼라 값을 예상하는 함수 인자에 범위가 지정될 때 자동적으로 암시적 교차를 수행하므로, 이전 Excel 동작은 지정된 범위를 공식 셀과 교차하고 지정된 범위와 교차하는 적절한 값을 사용합니다. 지정된 범위와 치수에 따라 수식 셀 행 또는 열을 선택합니다.
대부분의 경우 셀 범위는 한 행에 있는 셀의 범위 또는 한 열에 있는 셀의 범와 같은 고유한 교차점이 있어야 하므로 수직 또는 수평 값의 단차열 배열이어야 합니다.
동적 배열과 새로운 동작의 도입으로 SINGLE 함수를 지정해야 하거나 이전 범위 교차 동작이 필요하다고 명시적으로 지정하기 위해 새로운 @ 연산자를 사용하여 배열 인자를 가져오는 것 대신에 배열에 각 요소에 대해 수식을 계산하고 인접한 셀들에 결과 배열을 보여줍니다.
함수 인자에 대한 범위 참조를 포함하는 수식 또는 IRange.Formula 속성을 사용하여 코드에 설정된 수식은 계산과의 호환성을 유지하기 위해 범위 인자 앞에 @를 삽입하도록 자동적으로 수정됩니다.
새로운 동적 배열 기능과 결과를 보여주도록 사용하기 위한 수식을 설정하려면 새로운 IRange.Formula2 속성을 사용해야 합니다. 해당 공식은 아래와 같습니다.
[C#]
IWorkbook wb = fpSpread1.AsWorkbook(); // note: to set a Dynamic Array formula in code that is intended to "spill" you MUST use the new Formula2 property!
wb.Worksheets["SINGLE"].Range("C8").Formula2 = "{1,2,3,4,5}";
[VB]
Dim wb As IWorkbook = FpSpread1.AsWorkbook()
' note: to set a Dynamic Array formula in code that is intended to "spill" you MUST use the new Formula2 property!
wb.Worksheets("SINGLE").Range("C8").Formula2 = "{1,2,3,4,5}"

IRange.Formula 속성으로 보여질 배열 값 또는 범위 인자를 사용하여 수식을 설정하면 각 배열과 범위 참조 앞에 @를 삽입하도록 해당 수식이 자동으로 조정됩니다 .
이는 이러한 배열 값 또는 범위 인자를 사용할 때 생성된 레거시 수식으로 저장된 이전 스프레드 시트 문서에서 가져온 수식에 적용되는 것과 동일한 논리로, 해당 수식이 배열에서 첫 번째 값을 선택하거나 암시적으로 수식과 범위를 교차하게 합니다. 이제 이러한 배열 값 또는 범위 인자는 SINGLE 함수 또는 @연산자를 사용하여 이전과 같이 계산해야 합니다.
Formula2 대신 Formula 속성을 사용하여 위의 배열 값을 설정하면 수식 =@{1,2,3,4,5}가 생성되며 이는 셀 C8의 첫 번째 값만 표시하고 인접한 셀로 보여지지 않습니다.

Cell , Column 및 Row 와 같은 상위 레벨 랩퍼 오브젝트(wrapper object)에는 Formula2 속성이 없습니다. 이러한 객체를 사용하는 경우, 하드 코딩된 배열과 범위 참조 앞에 @를 삽입하도록 수식이 조정되지 않고 대신 동적 배열이 활성화된 경우 해당 공식이 인접한 셀에 보여집니다. WorkbookSet의 CalcFeatures 플래그를 사용하여 계산 엔진이 동적 배열 수식 및 동작을 활성화할지 여부를 제어할 수 있습니다 .
[C#]
fpSpread1.AsWorkbook().WorkbookSet.CalculationEngine.CalcFeatures = GrapeCity.Spreadsheet.CalcFeatures.DynamicArray;
[VB]
FpSpread1.AsWorkbook().WorkbookSet.CalculationEngine.CalcFeatures = GrapeCity.Spreadsheet.CalcFeatures.DynamicArray
셀 수식에서 새 SINGLE 함수를 사용하면 수식 함수를 단순화하기 위해 새로운 @ 연산자를 대신 사용하여 해당 구문으로 자동 대체됩니다. 아래 예제는 SINGLE 함수를 수평 및 수직 배열과 하드 코딩된 배열 값과 함께 사용하는 것을 보여줍니다 .

셀 D10=@C8#의 수식은 C8에서 G8까지 보여지는 가로 배열을 참조합니다. C8:G8 범위와 수식 셀 D10 사이의 교차점이 수식 셀인 D10과 함께 교차하는 범위 C8 : G8에 열이기 때문에. 셀 D8의 값을 반환하므로 결과는 2입니다. 셀 D11의 수식은 하드 코드화된 배열 값을 참조하며, 이 경우 배열의 첫 번째 항목인 1을 반환합니다. 셀 D15과 F15의 공식은 셀 B14의 수직 배열과 유사하게 동작합니다.
SINGLE 함수는 단일 셀로 여기는 교차 범위를 지정하여 셀의 범위에서 하나의 값을 선택하는 데 사용될 수 있습니다.

셀 C22의 수식은 C22:E24 범위의 인접한 셀에 보여지는 3x3값 배열을 반환합니다 .
해당 범위의 내용은 SINGLE 함수를 사용하여 두 가지 방식으로 미러링됩니다. 먼저 열 참조 C :C, D:D 및 E:E를 사용하여 G22 : I24 범위에서 수식 셀을 지정된 인접 열의 셀과 교차합니다. 기둥. 그런 다음 C27:E29 범위에서 다시 행 참조 22:22, 23:23 및 24:24를 사용하여 수식 셀을 지정된 인접행의 셀과 교차시킵니다.
각각의 경우 수식은 열 수식과 행 수식에 대해 복사해야 하므로 각 수식은 범위에서 단일 값을 반환하므로 각 공식에 대해 9개의 수식이 필요합니다.
종류
SORT 구문
| SORT (array, [sort_index], [sort_order], [by_col]) | |
| array | 정렬할 배열 또는 범위입니다. |
| [sort_index] | 정렬할 행 또는 열의 옵션 인덱스입니다 (기본값은 1). |
| [sort_order] | 내림차순으로 정렬하려면 옵션 -1 (기본값은 1, 오름차순) |
| [by_col] | 열을 기준으로 정렬하려면 TRUE를 선택합니다 (기본값은 FALSE, 행을 기준으로 정렬). |
정렬(SORT) 함수는 배열 또는 값의 범위를 사용하고 지정된 정렬 색인과 각 정렬 키에 대한 정렬 순서를 사용하여 컨텐츠에 대한 정렬을 수행합니다. 배열 인수는 하드 코딩된 값의 배열, 범위 참조 또는 값 배열을 초래하는 더 복잡한 표현식일 수 있습니다 (예 : UNIQUE 또는 SORTBY 와 같은 다른 동적 배열 함수 사용).
sort_index 및 SORT_ORDER 인자는 간단한 하나의 정렬의 경우 스칼라 값일 수 있으며, 이들은 다중 키 정렬에 사용할 각 정렬 키를 지정하는 배열 값이(동일한 길이이어야 함) 될 수 있습니다. by_col 인자는 정렬 인덱스를 사용하여 주요 열 인덱스를 지정하거나 대신 정렬이 행에서 수행될지 여부(기본 동작)를 지정하거나 정렬 인덱스를 사용하는 열에 의해 대신 키 열 인덱스를 지정합니다. 이 함수는 주요 열 또는 행이 테이블 데이터 내에 포함되어 있는 테이블의 내용과 같은 경우에 유용합니다.
테이블 데이터가 아닌 키 값을 기준으로 테이블 데이터를 정렬하는 경우 SORTBY 함수를 대신 사용해보세요(아래 참조).
아래 예제는 SortData 테이블을 사용합니다.

첫 번째 예는 ProductName 열을 기본 오름차순으로 정렬합니다.

다음 예는 수량 (Quantity)을 내림차순으로 정렬합니다.

마지막 예는 SalesPerson에서 오름차순으로 정렬한 다음 Quantity를 내림차순으로 정렬합니다.

정렬 기준
SORTBY 구문
| SORYBY (array, by_array1, [order_array1], [by_array2, order_array2],…) | |
| array | 정렬할 배열 또는 범위입니다 (필수). |
| by_array | 첫 번째 정렬 키의 범위 또는 배열입니다 (필수). |
| [order_array1] | 내림차순의 경우 옵션값은 -1 (기본값은 오름차순) |
| [by_array2 | 옵션적 배열 또는 두 번째 정렬 키의 범위. |
| order_array2] | -1은 내림차순, 1은 오름차순 (by_array2가 지정된 경우 필요) |
| 이 함수는 다음 정렬 키 범위와 순서를 지정하여 추가 인자를 쌍으로 사용할 수 있습니다. | |
SORTBY 함수는 배열 또는 범위의 일부가 아닌 키 열 또는 행에 의한 범위 또는 배열을 정렬 할 경우에 유용합니다. 이 함수는 by_array가 적절한 크기의 범위 또는 배열이 될 수 있기에 함수는 SORT 함수 보다 융통성이 있습니다.
아래 예제는 SortByData 테이블(명확성을 위해 SortData 테이블과 동일한 데이터를 포함함)을 사용합니다.

첫 번째 예는 ProductName 열을 기본으로 하여 오름차순으로 정렬합니다.

다음 예는 Quantity를 내림차순으로 정렬합니다.

마지막 예는 SalesPerson 에서 오름차순으로 정렬한 다음 Quantity을 기준으로 내림차순으로 정렬합니다.

정렬 키 범위에서 열 또는 행 인덱스를 지정하는 대신 SORTBY 함수를 사용하는 경우 SORT 함수를 사용하는 수식보다 훨씬 명확하고 읽기 쉬운 구조화된 테이블 참조를 전체 테이블 컬럼에 사용할 수 있습니다.
UNIQUE
UNIQUE 구문
| UNIQUE (array, [by_col], [unique_only]) | |
| array | 비교할 값 또는 벡터를 포함하는 범위 또는 배열입니다. |
| by_col | 열 또는 행 별로 값을 비교할지 여부(기본값은 FALSE, 행)입니다. |
| unique_only | 고유한 값 또는 벡터만 반환할지 여부 (정확히 한 번 발생하면 기본값은 FALSE 임)입니다. |
UNIQUE 함수 값의 배열 또는 범위를 사용하고 고유한 항목 배열을 반환합니다. 이 함수는 옵션값인 unique_only 인자에 값에 대해 TRUE 또는 FALSE를 지정했는지에 따라 "unique"의 정의가 유연해집니다. 만약 TRUE로 설정했을 경우, 함수는 배열에서 정확히 한 번만 발생하는 unique한 항목만 검색하고 해당 항목의 목록만 반환합니다. 그러나 기본 동작은 중복 배열을 정리하고 중복이 없는 원래 배열의 각 항목 목록을 반환하는 FALSE 입니다.
UNIQUE의 첫 번째 예는 배열 이 인접한 열에 보여지는 수평 배열일 때 by_col에 대해 TRUE를 지정하는 방법을 보여줍니다. 그렇지 않으면 UNIQUE가 unique 항목을 반환하지 않습니다.

다음의 UNIQUE 예제는 수직 배열로 작업하는 방법을 보여줍니다.

셀 E22 의 수식은 UNIQUE의 가장 일반적인 사용법을 보여줍니다. 하나의 열의 세로 배열 또는 셀 범위에 대한 참조를 지정하면 unique 항목의 "정리된" 목록을 반환하기 위해 다른 인wk가 필요하지 않습니다. 이것은 by_col에 대한 기본값 FALSE를 지정하는 셀 H22의 공식과 같습니다. 셀 K22 의 수식은 unique_only에 TRUE 를 사용하는 것을 보여주며,이 경우 범위 내에서 유일한 고유 값인 3 하나만 리턴합니다 .
배열에 인접한 행에 보여지는 수직 배열인 경우 by_col에 TRUE를 지정해서는 안 됩니다.

UNIQUE 함수는 2차원 배열 또는 셀 범위와 함께 사용하는 경우 더욱 복잡해집니다. 다음 예에서는 이 하드 코딩된 배열 참조= {1,1,2,1,3, 1,1,2,1, 3; 1,2,3,2,5; 1,2,3,2,5; 1,2,2,2,5} 인접 셀과 D29 : H33 범위를 채웁니다:

배열이 2 차원일 경우 by_col이 FALSE 이거나 지정되지 않았을 때 행 벡터 목록으로 처리되고, by_col 이 TRUE인 경우 열 벡터 목록으로 처리됩니다. 벡터 값 사이의 비교가 수행되며, 각각의 벡터 컴포넌트(해당 셀 값)가 동일할 때 두 벡터 값은 동일한 것으로 간주됩니다.
이 방법은 다소 복잡하기 때문에 예시를 명확하게 설명하기 위해 위의 배열을 참조하는 9가지 사례로 나누고 각 결과를 자세히 설명하겠습니다 .
사례 1은 단순히 D29# 범위를 참조하고 옵션 인자를 제외합니다.

by_col 및 unique_only 의 기본값이 모두 FALSE 이므로 3개의 unique한 행을 반환합니다. 다음 두 가지 경우인 2, 3과 관련이 있으며 해당 인자에 대한 기본값을 지정하여 동일한 결과를 표시합니다.


사례 4는 by_col에 FALSE 를 지정하고 unique_only을 TRUE를 지정한 결과를 보여주며, 하나의 고유한 행을 반환합니다.:

사례 5,6은 by_col에 대한 TRUE와 unique_only에 대한 FALSE가 명시적으로 지정한 결과에 대해서 보여주며, 사례 5에서는 기본 값을 사용하고 사례 6에서는 FALSE를 따라서 unique한 열을 반환합니다.


사례 7은 사례 1 , 2, 3과 동일한 결과를 보여주며, by_col은 기본값 FALSE를 사용하고 unique_only에 대해 FALSE를 지정합니다.:

사례 8은 by_col, unique_only에 대한 TRUE를 지정한 결과를 보여줍니다. 이 결과는 세 개의 고유한 열을 보여줍니다.

마지막으로 사례 9 는 사례 4와 동일한 결과를 보여주며, by_col은 기본값 FALSE를 사용하고 unique_only에 대해 TRUE 를 명시적으로 지정합니다.

댓글목록
등록된 댓글이 없습니다.


